

들어가며
인공지능(AI)이 우리의 업무 방식, 제품 개발, 의사결정에 변화를 일으키고 있는 지금, 많은 조직들이 범용 언어 모델을 도메인 특화된 용도로 맞춤화하는 방법을 모색하고 있습니다. 앞선 글에서는 대규모 재학습 없이도 자연어 명령을 따르게 할 수 있는 유연한 방식인 Instruction Tuning을 소개한 바 있습니다.
이번 글에서는 AI 시스템을 맞춤화하는 두 가지 강력하면서도 근본적으로 다른 접근 방식, **Fine-Tuning(파인튜닝)**과 **RAG(Retrieval-Augmented Generation)**을 살펴봅니다. 이 두 방식은 모두 대규모 언어 모델(LLM)을 특화된 용도로 조정하는 데 사용되지만, 작동 원리는 완전히 다릅니다. 특히 HR Tech, 법률, 의료와 같은 도메인에 효과적인 AI 솔루션을 구축하려면, 이 두 방식의 **트레이드오프(장단점)**를 정확히 이해하는 것이 중요합니다.
Fine-Tuning(파인튜닝)이란?
Fine-Tuning은 사전학습된 언어 모델을 특정 작업이나 도메인에 맞게 라벨링된 데이터셋으로 추가 학습시키는 방법입니다. 이 과정에서 모델의 내부 파라미터(가중치)가 업데이트되어 새로운 작업에서 더 나은 성능을 내도록 조정됩니다.
예를 들어, HR 분야에서는 수천 개의 익명 이력서를 모델에 학습시켜 후보자-직무 매칭 정확도를 높일 수 있습니다.
아래 그림은 이 과정을 시각적으로 설명합니다. 도메인 특화 데이터를 준비한 뒤 이를 구조화하여 모델의 추가 학습에 활용하고, 이로 인해 모델의 가중치가 조정되며 새로운 도메인에 특화된 결과를 낼 수 있도록 만드는 과정입니다. 이 사이클은 새로운 데이터가 확보될 때마다 반복 가능하며, 모델은 점진적으로 개선되고 변화하는 요구에 적응할 수 있습니다.

Open AI, Fine-Tuning (Image Reference-https://platform.openai.com/docs/guides/fine-tuning)
Fine-Tuning은 어떻게 작동할까?
1.
데이터 준비: 도메인 혹은 과업에 특화된 라벨링된 데이터셋을 구성
2.
모델 학습: 사전학습 모델을 기울기 기반 학습으로 가중치를 조정
3.
성능 검증: 과적합을 방지하기 위해 보지 않은 데이터로 성능을 평가
Fine-Tuning을 거친 모델은 기존의 베이스 모델과는 다르게 행동하며, 학습한 데이터에 특화된 형태로 바뀝니다.
RAG(Retrieval-Augmented Generation)이란?
RAG는 대규모 언어 모델(LLM)에 외부 지식 베이스를 결합하여 기능을 확장하는 방식입니다. 모델이 단순히 학습된 내용에 의존하는 것이 아니라, 실시간으로 관련 정보를 검색하여 응답 생성 전에 프롬프트에 삽입합니다.
이 방식은 특히 최신 정보나 세부적인 전문 지식이 중요한 분야에서 유용합니다.
예를 들어 RAG 기반의 HR 어시스턴트는 응답을 생성하기 전에 최신 노동법이나 사내 인사 정책을 검색하여 보다 정확하고 시의적절한 답변을 생성할 수 있습니다.
아래 이미지는 RAG가 LLM과 함께 작동하는 흐름을 단계적으로 설명한 개념도입니다.
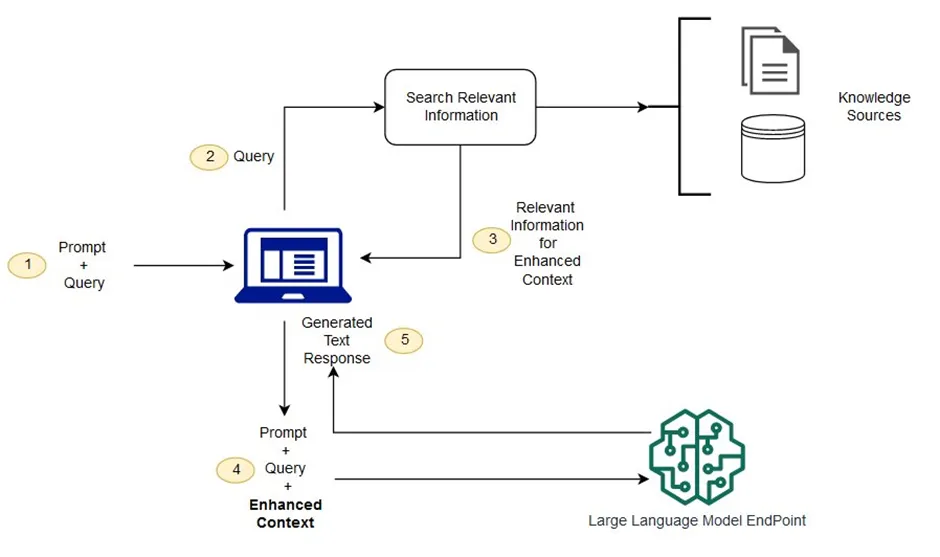
AWS, What is the RAG? (Image Reference-https://aws.amazon.com/what-is/retrieval-augmented-generation/)
RAG는 어떻게 작동할까?
1.
정보 검색 단계: 사용자의 질문에 따라 내부 지식베이스(예: 사내 문서)에서 관련 정보를 검색
2.
프롬프트 보강 단계: 검색된 문서를 질문에 덧붙여 LLM에 입력
3.
응답 생성 단계: LLM이 질문과 검색된 정보를 바탕으로 응답 생성
이 방식은 모델을 재학습시키지 않기 때문에, 범용성은 그대로 유지하면서도 도메인에 특화된 방식으로 작동합니다.
Fine-Tuning vs RAG: 주요 차이점 비교
항목 | Fine-Tuning | Retrieval-Augmented Generation (RAG) |
핵심 원리 | 모델 가중치 수정 | 외부 지식을 실시간 주입 |
데이터 요구사항 | 라벨링된 학습 데이터 필요 | 고품질 지식베이스 필요 |
적응성 | 학습된 작업에 매우 특화 | 범용 모델에 유연하게 정보 접근 가능 |
지식 갱신 방법 | 재학습 필요 | 문서만 수정하면 즉시 반영 |
활용 예시 | 이력서 분류, 스킬 추출 | 정책 Q&A, 실시간 컴플라이언스 어시스턴트 |
Fine-Tuning의 장점과 한계
장점
1.
높은 정확도: 반복적이고 구조화된 작업에 강력한 성능 발휘
2.
추론 속도 우수: 검색 과정이 없기 때문에 빠르게 결과 도출
3.
도메인 특화: 내부 패턴을 깊이 있게 학습 가능
한계
1.
훈련 비용 높음: 계산 자원과 시간이 많이 소요됨
2.
지식 고정: 도메인 정보가 바뀌면 재학습이 필요함
3.
과적합 위험: 특히 데이터가 적거나 품질이 낮을 경우
RAG의 장점과 한계
장점
1.
지식의 최신성 유지: 실시간으로 최신 정보에 접근
2.
학습 부담 적음: 모델 가중치를 변경할 필요 없음
3.
설명 가능성 향상: 검색된 콘텐츠를 응답과 함께 제공 가능
한계
1.
검색 품질 의존도 높음: 검색이 부정확하면 응답도 부정확
2.
지연 시간 발생: 검색 단계로 인해 응답 속도 약간 느림
3.
구조 복잡성: 문서 인덱싱, 임베딩, 검색 파이프라인 필요
언제 어떤 방식을 써야 할까?
상황 | 추천 방식 |
대규모 라벨링 데이터와 고정된 과업이 있을 때 | Fine-Tuning |
빠르게 변하는 정보가 반영되어야 할 때 | RAG |
문서 기반 설명이 필요한 환경 | RAG |
경량화된 고속 배포가 필요한 경우 | Fine-Tuning |
응답마다 근거를 반드시 제시해야 하는 고위험 환경 | RAG |
다음 글 예고: AI 에이전트 실전 활용
다음 글에서는 AI 에이전트의 개념을 소개할 예정입니다.
AI 에이전트는 특화된 모델로 구성된 모듈형 자율 시스템으로, 이력서 필터링부터 정책 상담, 팀 간 협업까지 다양한 작업을 수행합니다. 이 에이전트들은 서로 상호작용하며 판단하고, 복잡한 파이프라인을 따라 작업을 위임할 수 있습니다.
이 글에서는 Fine-Tuning과 RAG가 이러한 AI 에이전트를 구성하는 데 어떻게 기여하는지,
에이전트를 효과적으로 조율하려면 어떤 조건이 필요한지,
그리고 에이전트 기반 아키텍처가 HR Tech를 포함한 다양한 산업에서
지능형 자동화의 새로운 패러다임을 어떻게 이끌고 있는지를 깊이 있게 다룰 예정입니다.
 AI가 어떻게 사고하고, 대화하며, 협업하는지 궁금하다면 다음 편도 놓치지 마세요!
AI가 어떻게 사고하고, 대화하며, 협업하는지 궁금하다면 다음 편도 놓치지 마세요!References
•
Lewis, P. et al. (2020). Retrieval-augmented generation for knowledge-intensive NLP tasks. arXiv:2005.11401
•
Raffel, C. et al. (2020). Exploring the limits of transfer learning with a unified text-to-text transformer. JMLR
•
OpenAI. (2023). Fine-Tuning Guide for GPT Models

